Annotation Services
- Bounding Box
- Polygon
- 3D LiDAR
- Geospatial
- Line Annotation
- Autonomous Vehicle
- Image Annotation
- Image Masking
- Cuboid Annotation
- Semantic Segmentation
- Video Annotation
- Key Point Annotation
- Text Annotation
- Audio Annotation
- Instance Segmentation
- Data labelling Services
- Image Classification Services
- Image Recognition Services
- Image Processing Services

Key Point Annotation
Key Point annotation is a more detailed protocol of image annotation used to detect small objects and shape variations by marking locations of Key Points. Key Point annotations are used to label a single pixel in the image to portray an object's shape. It is a very precise technique that has its uses in movement tracking and prediction, human body parts detection, emotion, gesture and facial recognition. It is commonly used in sports and security.
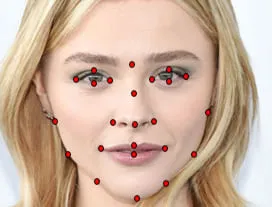
Face Annotation

Object Landmark

Hand Annotation
Image Annotation Techniques
Artificial intelligence requires human intervention . The goal of image annotation is to assign relevant, task-specific labels to images so that it is easily understood by the AI. The Image segmentation process consists of the following techniques:
- Image classification: Identify the contents of the image such as person, car, tree, etc.
- Object Detection: It is a method to identify and correctly label every object present in an image frame.
- Object Detection: It is a method to identify and correctly label every object present in an image frame.
- Image Classification: Labelling the object.
- Semantic Segmentation: It involves detecting objects within an image and putting them in groups of defined categories such as Humans, Vehicles, Traffic lights, etc.
- Instance Segmentation: It can be considered a refined version of Semantic Segmentation. It involves identifying each object instance for every known object within an image. That means it treats multiple objects of the same group as separate objects.
- Panoptic Segmentation: It is a combination of Instance and Semantic Segmentation. Each pixel is associated with two values- its group label and an instance number. It can also recognize the background elements like sky, road, grass, etc.
- Key Point Annotation / Landmark Recognition: It involves setting up a skeletal structure of the image. Comparing the nodes and edges that compose the 'skeleton' of an object is accomplished through Key Point annotation. This can then be used to track the shapes of specific objects by allowing the neural network to recognize essential points of interest in the input image. The neural network outputs the coordinates (x, y) of key points. By tracking multiple Key Points, facial features and emotions can easily be recognised. It can also be used to identify tactical weaknesses by combining it with other annotation techniques.
This broadly consists of two steps
Bounding Boxes For Image Tagging In Retail & E-commerce:
Bounding box Annotation is also helpful for the fashion industries as they visualize the items that are sold at online stores. It highlights the fashion and clothing accessories with automatic tagging to make them visible and easily accessible for visual search. It also helps in annotating the goods and detecting the items like fashion accessories and furniture that are to be picked from the shelf for automatic billing in retail shops. Bounding box annotation is used to detect different objects from the most complex images to enhance the visual search ability of the model.
Why Annotation Support for Bounding Box Annotation?
We at annotation support employ advanced tools and techniques in order to provide a fine-quality bounding box annotation solution. Some of the features that set us apart from various other Bounding Box services:
- Quality with Accuracy: We at Annotation Support avail you of the best-in-class quality services while attaining the next level of accuracy. We tend to deliver excellent bounding box annotation employing multiple stages of reviewing and auditing of labelled data.
- Security with Privacy: Annotation Support is certified for maintaining the highest standards of data privacy and security. We ensure the confidentiality of all our clients.
- Fully Scalable Service: Our team of highly skilled and experienced workers tend to annotate the image according to the demand of the clients. All the needs are met by us within the timeframe, hence enabling a completely scalable solution.
- Cost-effective Pricing: We offer our clients the most affordable bounding box annotation service to help them get the best solution while aligning with the budget.
Key Point Annotation in Sports
One of the major applications of Key Point annotation is in the field of sports. Modern athletes require the latest technology to complement their physical training. Incorporating image annotation for analyzing performances is an example of that. Key Point annotation can be used to track and recognize miniscule performance improvements that may go unmissed by the human eye. It can also provide an early warning system for various types of injuries. Image annotation helps athletes to compete at the highest level and maintain consistent performance there.
Challenges with Key Point annotation
- Time: Manually annotating key points in an image is a time consuming task. Machine learning requires a huge amount of training data. It requires a lot of time and patience to accurately effectively label the image-based datasets.
- Computational Complexity: Any kind of error while labeling key points can affect the training process and ruin the whole work.
- Domain Knowledge: High domain knowledge in a given field is often required to assign accurate labels. Annotators should know what to label and have some level of expertise in the particular field.
Why Annotation Support?
We will design a workflow that ensures strict adherence to quality guidelines provided by our customers. We have meticulously assembled a specialist team of annotators for any type project using a stringent testing process. To deliver our quality data sets, we employ a combination of custom automated checks and expert human evaluation to rectify any errors in the annotated data.Particular attention is paid to Key Point visibility and consistency in both individual frames and the dataset as a whole. This produces annotations that track movement to a high degree of accuracy.
Frequently Asked Questions
Find answers to the most commonly asked questions about our annotation services.
